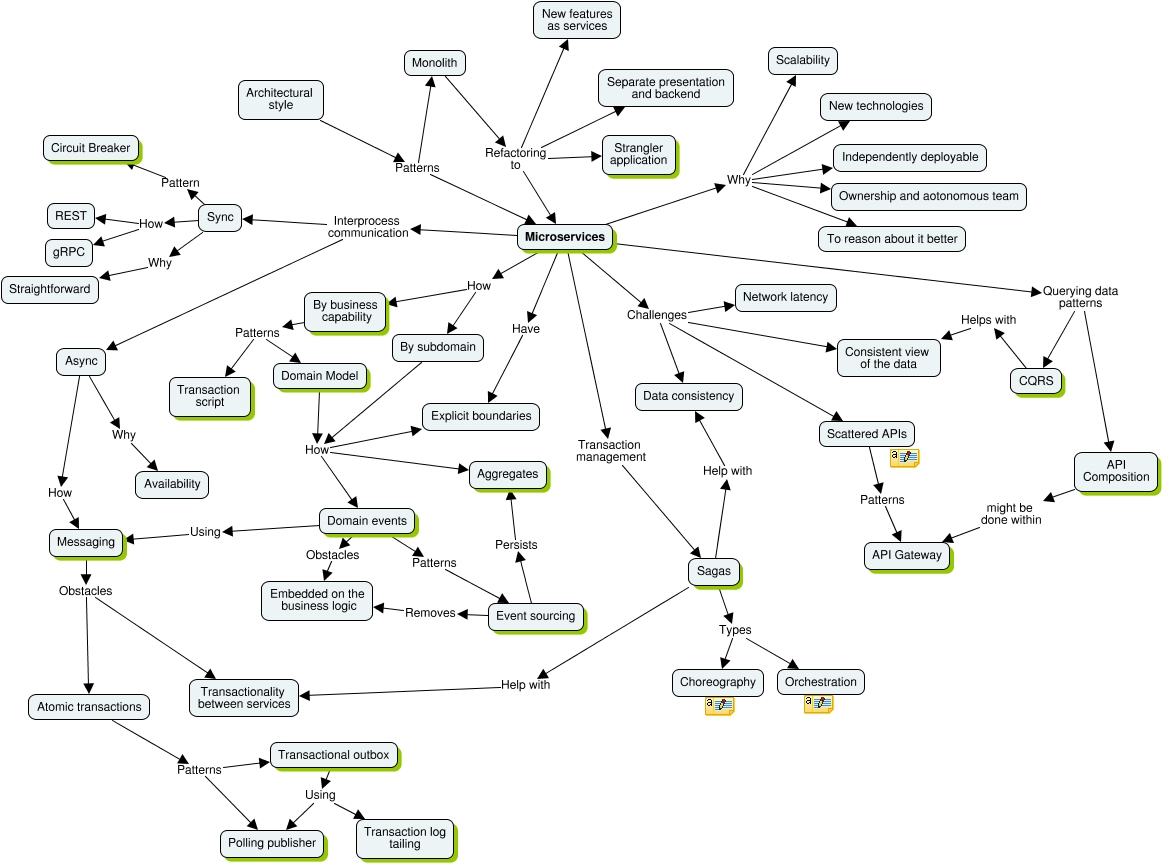
One of the hardest tasks when moving into a monolithic to a microservice architecture is to separate the data owned by each microservice. Usually, the data is placed in one database schema and the goal when extracting microservices will be partition it accordingly without causing major issues. Sam Newman describes a few patterns in his book Monolith to
Microservices Evolutionary Patterns to Transform Your Monolith that would help with the task and I would like to give them briefly.
Shared source of truth
The preferable option when extracting new microservices is also to move the data apart but that is not always possible to achieve, these patterns add options when facing this of scenario.
Shared Database
Multiple microservices use the same database as a source of truth.
It might be useful when the data to be accessed is read-only and highly stable or when the database is exposed as an endpoint (only read-only) to fulfil reporting needs or clients joining large amounts of data.
Database view
Exposing different database views for each service might be useful to limit the data that services can access.
Applying this pattern could help when the existing schema is difficult to decompose. If the end goal is to push for a full schema decomposition this pattern should be avoided.
Database wrapping service
It might be useful to add service as a wrapper of the database schema when is difficult to pull apart. This pattern will hide the database behind a service and introduce well define APIs. Clients that need the data can now consume the new service. This pattern intends to encourage people to stop making changes to the database and push for their services.
Database as service interface
With this pattern, there is a copy of the database in read-only mode. The new database is exposed directly to clients. This might be useful when dealing with reporting. An important obstacle that needs to be taken under consideration is the need for a mapping engine that will populate the new database from the source database.
Physical or logical split?
Given the number of databases schemas are going to increase when splitting the monolith there are two options to consider if the databases share the same technology:
- Have one single database engine with multiples schemas. By doing this there is only one point of failure.
- Have different database engines for each schema with the cost involved in it.
Splitting the database first
Repository per bounded context
Usually, within the monolith, the data access component is a big component. Instead of having that single repository layer, there are multiples components by bounded context. This technique helps to realise what data is needed in each bounded context and it is useful when looking into split the monolith to have a better understanding about what tables need to be moved apart as a new schema.
Database per bounded context
Each bounded context has its database schema. This pattern is useful when the application is supposed to be split in the future into microservices. It is recommended to follow this approach when building new systems since with little effort developers will have more options available in the future.
Splitting the code first
Aggregate exposing monolith
This pattern might be useful if the extracted microservice needs data owned by the monolith. Instead of accessing the data directly, the monolith exposes an API that is consumed by the new microservice. It also might help to discover other candidates to be extracted.
Multischema storage
This pattern fits in the scenario where the data owned by the microservice still lives under the monolith. The pattern can be applied when there is a new business capability for the microservice that need to add data into the schema. The new data should be added in the microservice schema instead of adding it into the monolith. This could open the door to move the entire data set out of the monolith.
Where to put shared static data?
This is a recurrent problem that can be solved with several approaches, let’s take a look.
Duplicate static reference data
It might be useful when not all services need to have the same data. Answering these question should give a hint if we could apply it: How often does the data change and how consistent need to be across services?
Dedicated reference data schema
The data is placed under the same schema and is accessed by multiple services. Use it when changes are unlikely to happen. Take into account that a change in the schema might impact multiple services.
Static reference data library
Share the static data as a library might be an option for a small amount of data where different services can see multiple versions of that data.
Static reference data service
This option is obvious, the shared static data lives under a microservice who owns the data. This option might be feasible for organizations where creating a new microservice does not involve too much overhead.
In the next post, I’ll try to describe a few techniques to migrate data from the monolith database into the new schemas.
]]>
 Provided by
Provided by  Provided by
Provided by